生存分析 Step 3.1:中介分析案例教程
survival-analysis-step3-1-zh.Rmd为什么需要这篇案例教程
Step 3.0 主要回答“中介分析是什么”。Step 3.1 的重点是把它真正用起来。
这里我们不只是演示怎么调用 leo_cox_mediation(),而是要把
5 个最容易卡住的问题讲清楚:
- 现在到底在问什么科学问题?
-
x_exp_a0、x_exp_a1、x_med_cde、x_cov_cond怎么映射到这个问题? - 什么时候应该用
mreg = "linear",什么时候应该用mreg = "logistic"? - 当
yreg = "auto"从survCox切到survAFT_weibull时,结果应该怎么读? - 不同场景下,科学解释为什么会变?
先固定一条科学主线,再改变分析场景
整篇案例围绕同一个问题:
更高代谢风险与事件结局的关联,是否有一部分是通过炎症路径传递的?
我们只改变两件事:
- 中介变量是按连续生物标志物,还是按阈值状态定义
- 结局是稀有事件,还是相对常见事件
set.seed(20260324)
make_mediation_case <- function(n = 1500, base_log_hazard = -5.8, censor_rate = 0.06) {
age <- rnorm(n, 60, 8)
sex <- factor(sample(c("女性", "男性"), n, replace = TRUE))
smoking <- factor(sample(c("从不", "曾经当前"), n, replace = TRUE, prob = c(0.6, 0.4)))
sex_num <- as.integer(sex == "男性")
smoking_num <- as.integer(smoking == "曾经当前")
metabolic_risk_num <- rbinom(
n, 1,
plogis(-0.3 + 0.03 * (age - 60) + 0.30 * sex_num + 0.35 * smoking_num)
)
inflammation_score <- rnorm(
n,
mean = 0.85 * metabolic_risk_num + 0.04 * (age - 60) + 0.35 * smoking_num,
sd = 0.9
)
hazard_rate <- exp(
base_log_hazard +
0.55 * metabolic_risk_num +
0.24 * inflammation_score +
0.02 * (age - 60) +
0.20 * smoking_num
)
event_time <- rexp(n, rate = hazard_rate)
censor_time <- rexp(n, rate = censor_rate)
data.frame(
incident_event = as.integer(event_time <= censor_time),
followup_years = pmin(event_time, censor_time),
metabolic_risk = factor(
metabolic_risk_num,
levels = c(0, 1),
labels = c("较低风险", "较高风险")
),
inflammation_score = inflammation_score,
inflammation_group = factor(
as.integer(inflammation_score > 0.5),
levels = c(0, 1),
labels = c("较低炎症", "较高炎症")
),
age = age,
sex = sex,
smoking = smoking
)
}
rare_case <- make_mediation_case(base_log_hazard = -5.8, censor_rate = 0.06)
common_case <- make_mediation_case(base_log_hazard = -4.6, censor_rate = 0.06)
data.frame(
场景 = c("稀有结局场景", "常见结局场景"),
样本量 = c(nrow(rare_case), nrow(common_case)),
事件数 = c(sum(rare_case$incident_event), sum(common_case$incident_event)),
`事件率` = c(fmt_pct(mean(rare_case$incident_event)), fmt_pct(mean(common_case$incident_event)))
)
#> 场景 样本量 事件数 事件率
#> 1 稀有结局场景 1500 131 8.7%
#> 2 常见结局场景 1500 339 22.6%其中稀有结局场景会让 yreg = "auto" 继续走
survCox,因为过滤并完成 complete-case
之后的分析集事件率仍不超过 10%;常见结局场景则是故意让
同一条科学问题切换到 AFT 路线。
案例 1:把炎症当作连续生物标志物
这是最符合“炎症是一个连续生物学过程”这一设定的场景。
x_med_cde_case1 <- stats::median(rare_case$inflammation_score, na.rm = TRUE)
res_case1 <- leo_cox_mediation(
df = rare_case,
y_out = c("incident_event", "followup_years"),
x_exp = "metabolic_risk",
x_med = "inflammation_score",
x_cov = c("age", "sex", "smoking"),
x_exp_a0 = 0,
x_exp_a1 = 1,
x_med_cde = x_med_cde_case1,
x_cov_cond = list(age = 60, sex = "女性", smoking = "从不"),
mreg = "linear",
yreg = "auto",
interaction = TRUE,
verbose = FALSE
)
case1_eval <- res_case1$evaluation
case1_te <- get_effect_row(res_case1, "te")
case1_tnie <- get_effect_row(res_case1, "tnie")
case1_pm <- get_effect_row(res_case1, "pm")
case1_te_ci <- case1_te[["95% CI"]][1]
case1_tnie_ci <- case1_tnie[["95% CI"]][1]
case1_pm_ci <- case1_pm[["95% CI"]][1]先把评价点和模型设定读成人话
res_case1$evaluation[, c(
"exposure_contrast", "x_exp_a0", "x_exp_a1",
"mediator_reference", "x_med_cde", "x_cov_cond",
"mreg", "yreg", "interaction"
)]
#> exposure_contrast x_exp_a0 x_exp_a1 mediator_reference x_med_cde
#> 1 较低风险 -> 较高风险 0 1 0.568 0.5680312
#> x_cov_cond mreg yreg interaction
#> 1 age=60.000; sex=女性; smoking=从不 linear survCox TRUE这张表其实已经把 3 个最重要的用户参数解释清楚了:
-
x_exp_a0 = 0、x_exp_a1 = 1表示这里比较的是较低风险 -> 较高风险 -
x_med_cde = 0.568表示 CDE 是在炎症评分中位数这个位置上评价的 -
x_cov_cond = age=60; sex=女性; smoking=从不表示这些效应是对这个协变量画像来算的,而不是一个“脱离人群背景”的抽象数值
所以这里的 CDE 可以直接翻成人话:
如果我们比较两个其他条件相同的 60 岁、女性、从不吸烟者,只让她们的代谢风险从较低风险变成较高风险,同时把炎症评分都固定在 0.568,那么还剩下多大的直接效应?
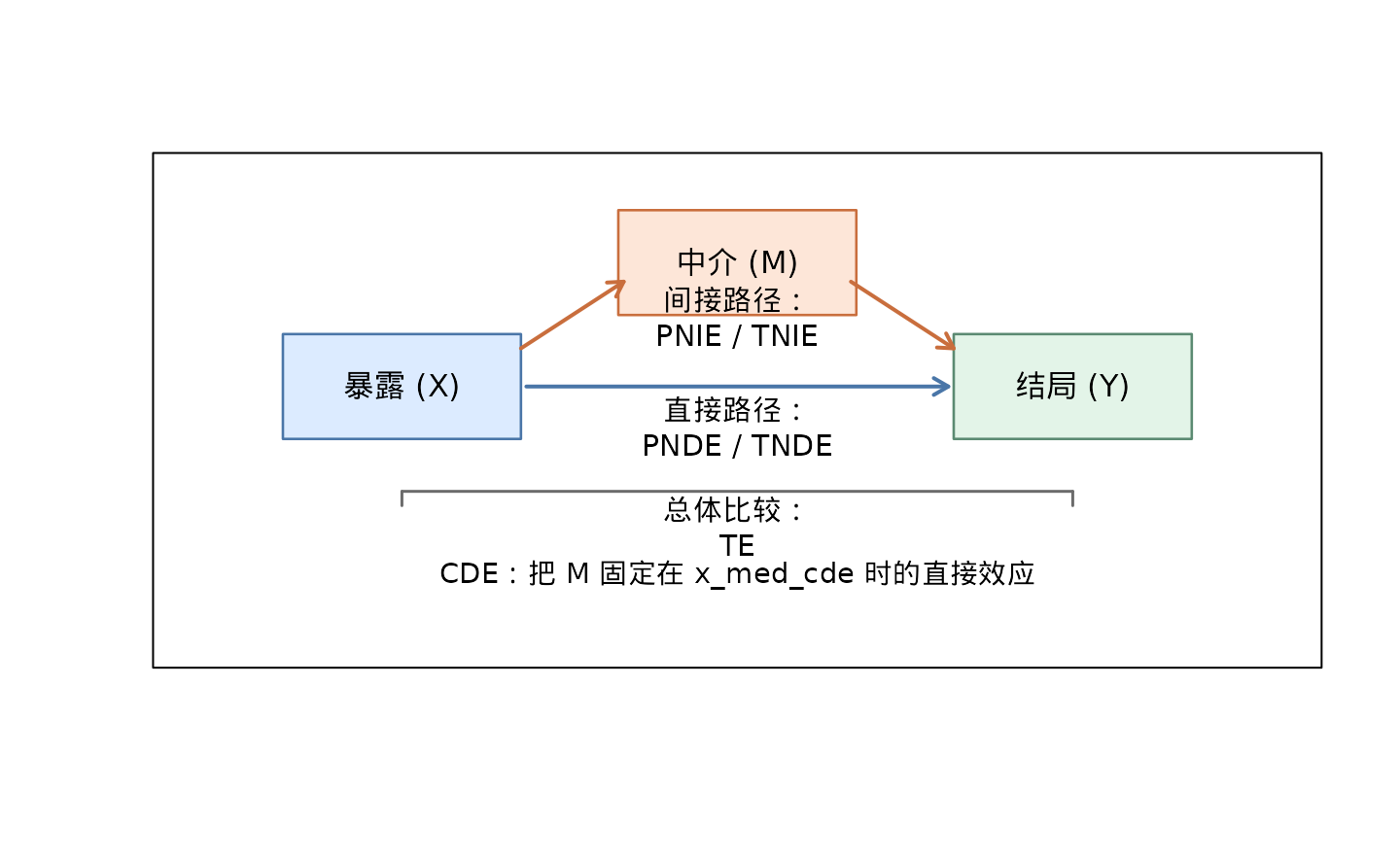
先记住这张最简的指标地图
| 缩写 | 全称 | 在教程里怎么读 |
|---|---|---|
| TE | Total Effect | 总关联有多大 |
| TNIE | Total Natural Indirect Effect | 通过中介路径传递了多少 |
| PNDE | Pure Natural Direct Effect | 不经过中介还剩多少 |
| PM | Proportion Mediated | 总效应里有多少比例像是经过中介 |
| CDE | Controlled Direct Effect | 把中介固定在 x_med_cde 后还剩多少直接效应 |
| TNDE | Total Natural Direct Effect | 另一种 natural 直接效应定义 |
| PNIE | Pure Natural Indirect Effect | 另一种 natural 间接效应定义 |
大多数论文第一次读结果时,通常先看
TE、TNIE、PNDE 和
PM。 CDE
只有在科学问题明确关心“把中介固定在某个水平”时才会成为重点。
这也就是为什么结果表里的 Mediator reference 只会出现在
cde 行:只有 controlled direct effect
需要先指定一个固定的中介值。
在解释中介分解前,先看数据是不是支持这条生物学故事
先看连续炎症评分在两组暴露人群里的分布。
ggplot2::ggplot(
rare_case,
ggplot2::aes(x = metabolic_risk, y = inflammation_score, fill = metabolic_risk)
) +
ggplot2::geom_violin(trim = FALSE, alpha = 0.35, color = NA) +
ggplot2::geom_boxplot(width = 0.16, outlier.alpha = 0.15, color = "#1f1f1f") +
ggplot2::scale_fill_manual(values = c("#5B8FF9", "#D14A61")) +
ggplot2::labs(
title = "较高风险组的炎症评分整体更高",
x = "代谢风险分组",
y = "炎症评分"
) +
ggplot2::theme_minimal(base_size = 12) +
ggplot2::theme(legend.position = "none")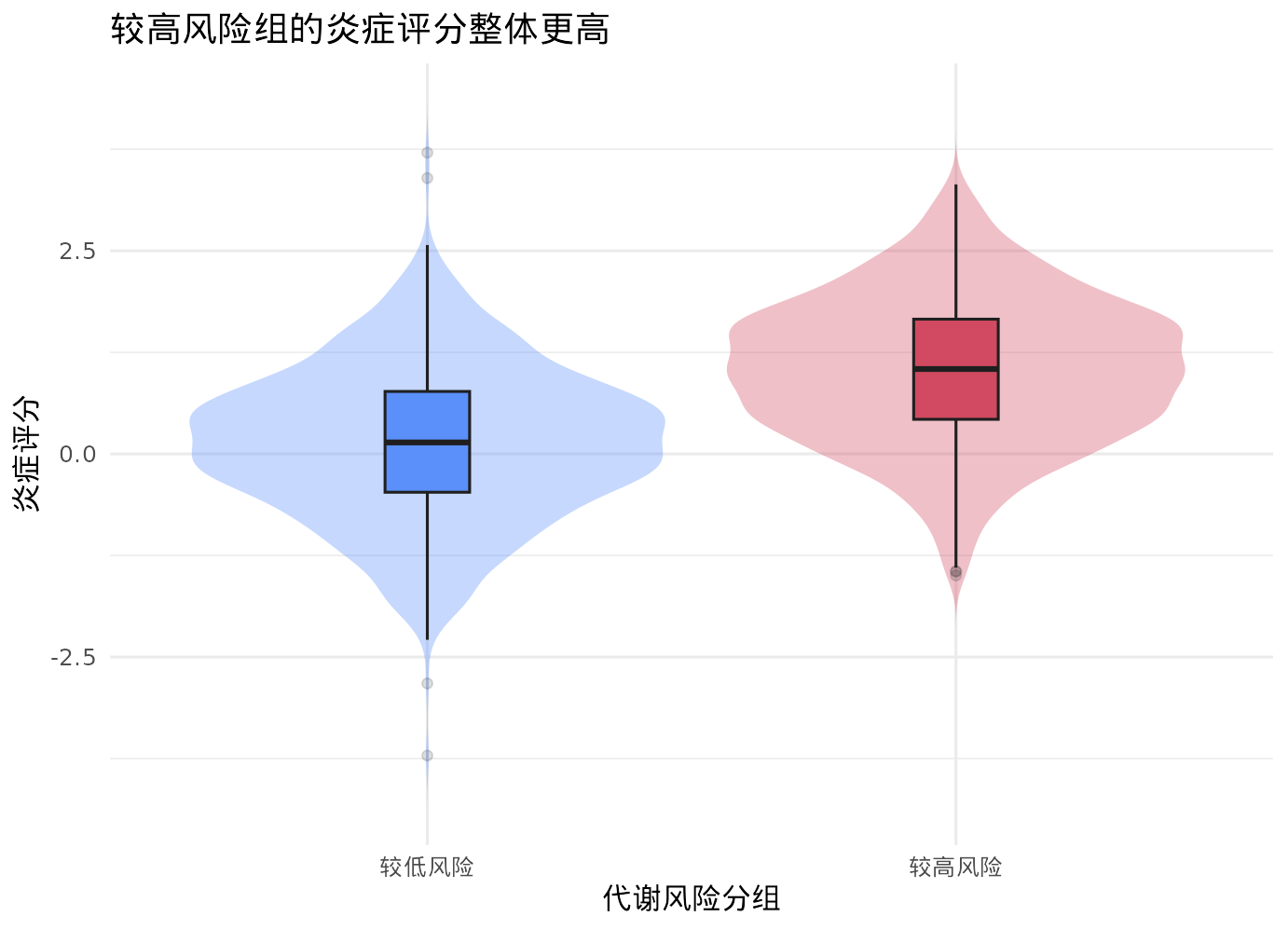
再看用阈值化炎症分组后,粗事件率在 joint stratum 里是不是也有一致方向。
joint_event_case1 <- dplyr::summarise(
dplyr::group_by(rare_case, metabolic_risk, inflammation_group),
n = dplyr::n(),
event_rate = mean(incident_event),
.groups = "drop"
)
ggplot2::ggplot(
joint_event_case1,
ggplot2::aes(x = inflammation_group, y = event_rate, fill = metabolic_risk)
) +
ggplot2::geom_col(position = ggplot2::position_dodge(width = 0.7), width = 0.62) +
ggplot2::geom_text(
ggplot2::aes(label = paste0(fmt_pct(event_rate), "\n(n=", n, ")")),
position = ggplot2::position_dodge(width = 0.7),
vjust = -0.15,
size = 3.3
) +
ggplot2::scale_fill_manual(values = c("#5B8FF9", "#D14A61")) +
ggplot2::scale_y_continuous(
labels = function(x) paste0(round(100 * x), "%"),
limits = c(0, max(joint_event_case1$event_rate) * 1.18)
) +
ggplot2::labs(
title = "较高风险且较高炎症组的粗事件率最高",
x = "炎症分组",
y = "观察到的事件率",
fill = "代谢风险"
) +
ggplot2::theme_minimal(base_size = 12)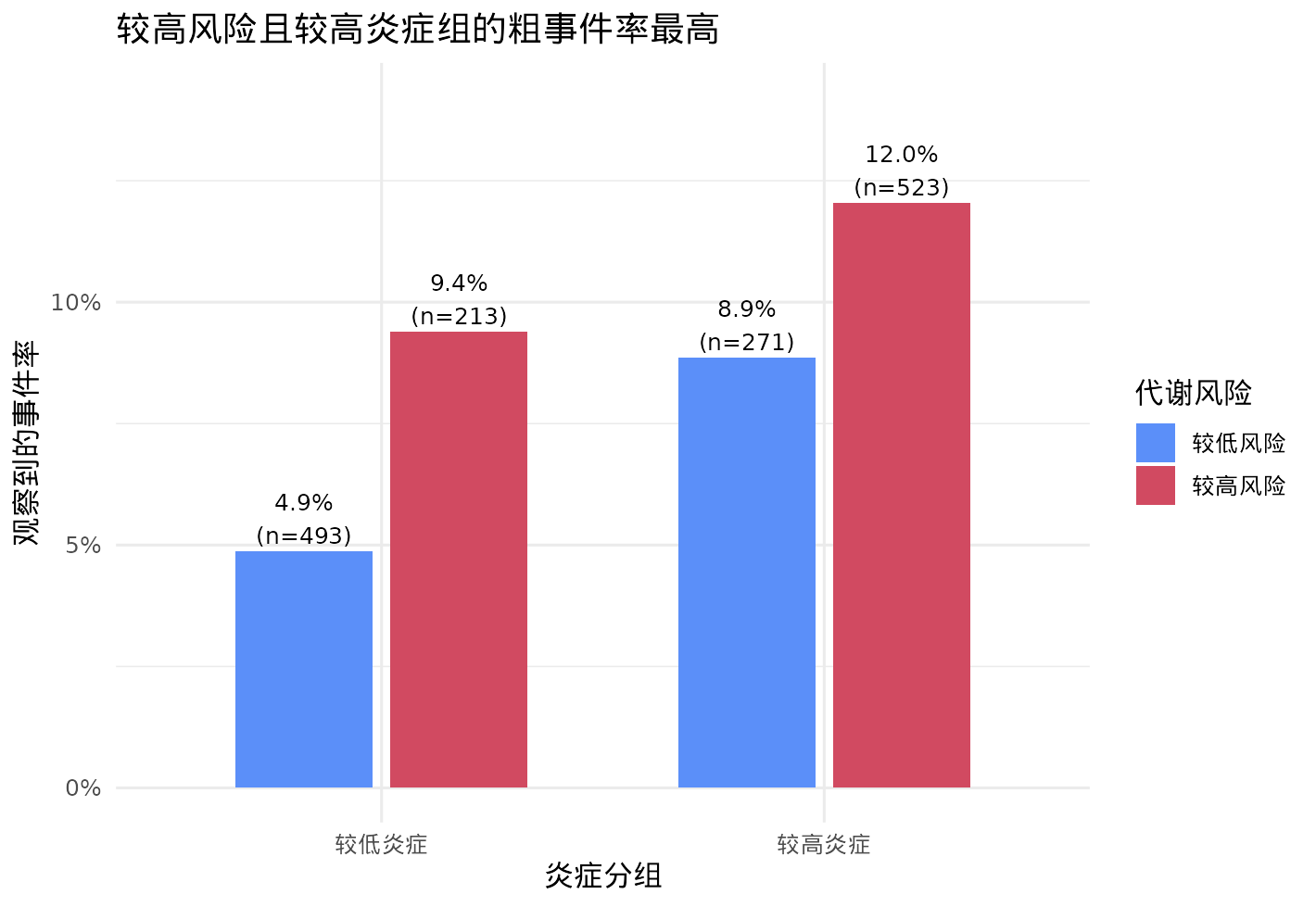
这张图本身并不能“证明交互”,但它说明为什么这里把
interaction = TRUE
作为默认设定是合理的:我们没有强行假设代谢风险的效应在所有炎症水平上都完全一样。
只解读真正跑出来的中介结果
dplyr::filter(res_case1$result, `Effect code` %in% c("te", "tnie", "pm"))
#> Model Effect code Effect Scale Exposure
#> 1 model_1 tnie Total natural indirect effect Hazard ratio metabolic_risk
#> 2 model_1 te Total effect Hazard ratio metabolic_risk
#> 3 model_1 pm Proportion mediated Proportion metabolic_risk
#> Mediator Outcome Exposure contrast Mediator reference
#> 1 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> 2 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> 3 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> N Case N Non-event N Total follow-up Estimate 95% CI P value
#> 1 1500 131 1369 23086.95 1.246 1.018, 1.525 0.033
#> 2 1500 131 1369 23086.95 1.877 1.303, 2.703 <0.001
#> 3 1500 131 1369 23086.95 0.423 0.027, 0.820 0.036
#> Mediator model Outcome model
#> 1 linear survCox
#> 2 linear survCox
#> 3 linear survCox因为这是稀有结局场景,所以这里的比值尺度应读作危险比(hazard ratio)。
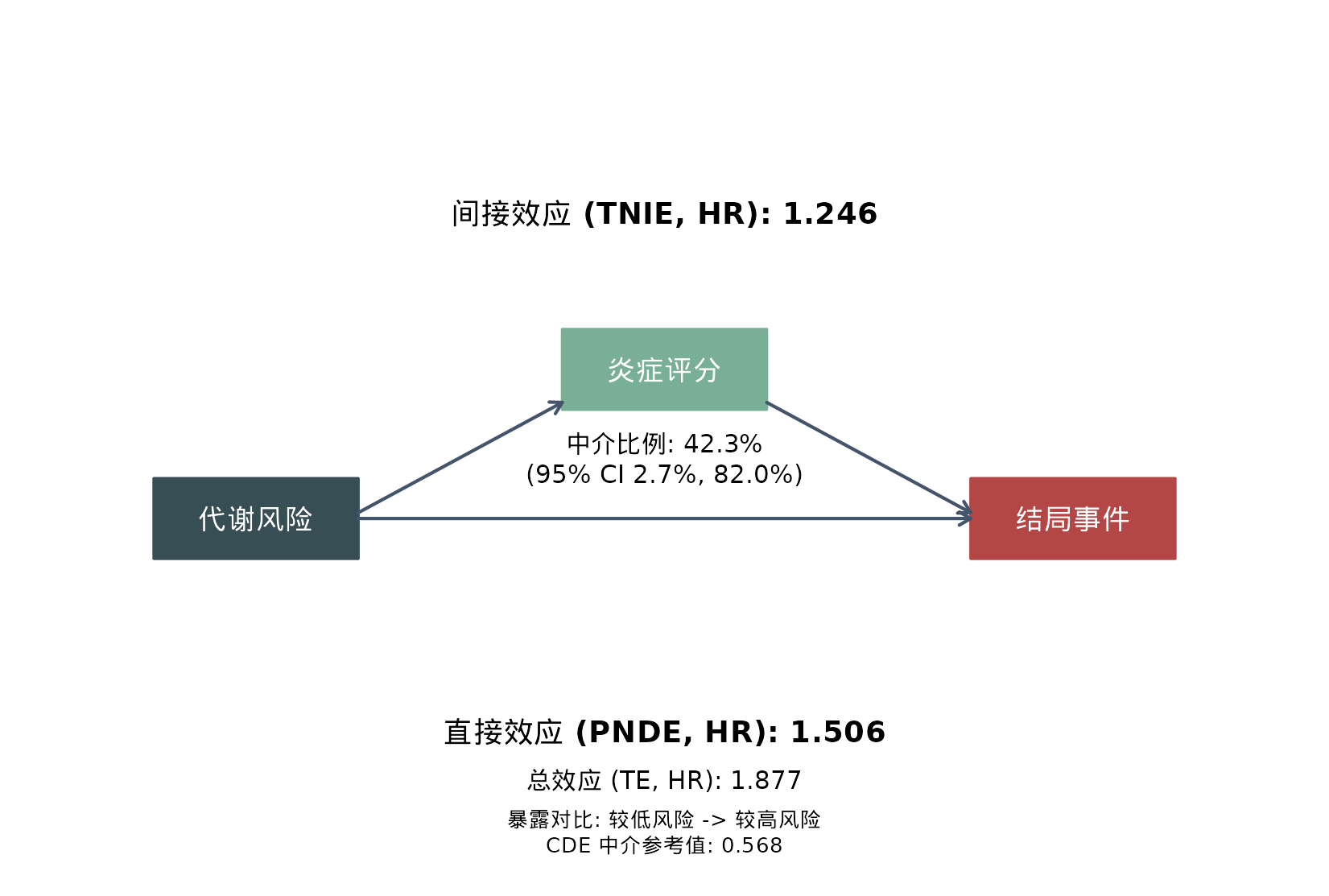
对这个拟合结果,更稳妥的人话解读是:
- 总效应
te = 1.877(1.303, 2.703)提示较高风险组总体事件瞬时风险更高 - 通过连续炎症评分这条路径的间接效应
tnie = 1.246(1.018, 1.525)也指向同方向风险升高 - 中介比例
pm = 42.3%(0.027, 0.820)说明在这个模拟队列里,炎症可能解释了总关联中相当可观的一部分
这里 pm 的置信区间整体仍在 0
以上,因此这个模拟示例更接近“存在正向中介占比”的模式,而不是“中介比例可能为
0”的不确定场景。
更接近论文语言的一句话可以写成:
在这组模拟数据中,较高代谢风险与更高事件瞬时风险相关,并且结果与“炎症评分承担了其中一部分路径”这一解释一致。
路径图可以把同样的结果更直观地展示出来。
leo_cox_mediation_plot(
x = res_case1,
exposure_label = "代谢风险",
mediator_label = "炎症评分",
outcome_label = "结局事件",
language = "zh",
palette = "jama"
)
案例 2:把同一条炎症路径改成阈值型中介
有时研究问题并不是“炎症越高越危险”,而是“是否进入高炎症状态”。这时
中介变量就更像一个阈值型状态,mreg 也应切到
logistic。
res_case2 <- leo_cox_mediation(
df = rare_case,
y_out = c("incident_event", "followup_years"),
x_exp = "metabolic_risk",
x_med = "inflammation_group",
x_cov = c("age", "sex", "smoking"),
x_exp_a0 = 0,
x_exp_a1 = 1,
x_med_cde = "较高炎症",
x_cov_cond = list(age = 60, sex = "女性", smoking = "从不"),
mreg = "logistic",
yreg = "auto",
interaction = TRUE,
verbose = FALSE
)
case2_tnie <- get_effect_row(res_case2, "tnie")
case2_pm <- get_effect_row(res_case2, "pm")
dplyr::bind_rows(
case_summary_row(res_case1, "案例 1:稀有结局 + 连续中介"),
case_summary_row(res_case2, "案例 2:稀有结局 + 二分类中介")
)
#> 场景 事件率 结局模型 总效应
#> 1 案例 1:稀有结局 + 连续中介 8.7% survCox 1.877 (1.303, 2.703)
#> 2 案例 2:稀有结局 + 二分类中介 8.7% survCox 1.878 (1.304, 2.706)
#> 间接效应 中介比例
#> 1 1.246 (1.018, 1.525) 42.3% (2.7%, 82.0%)
#> 2 1.100 (0.920, 1.315) 19.5% (-16.4%, 55.4%)这里最值得学习的不是“谁更显著”,而是科学问题怎么变了。对于
logistic 中介,x_med_cde
现在应该写原始观测水平,而不是内部 0/1 编码:
- 案例 1 问的是连续生物标志物路径,所以间接效应为 1.246,中介比例为 42.3%
- 案例 2
问的是阈值状态路径,所以同一条大方向故事会变成更弱、也更不精确的结果(
tnie= 1.100,pm= 19.5%)
这并不表示二分类中介一定不好,而是说明:
- 如果生物学过程本来就是连续梯度,二分法可能会损失路径信息
- 如果你的科学问题本来就是“是否进入高炎症状态”,那二分类中介反而更贴题
案例 3:同一条路径问题,但结局不再稀有
现在只改变一件事:让结局更常见,看看 yreg = "auto"
会发生什么。
res_case3 <- leo_cox_mediation(
df = common_case,
y_out = c("incident_event", "followup_years"),
x_exp = "metabolic_risk",
x_med = "inflammation_score",
x_cov = c("age", "sex", "smoking"),
x_exp_a0 = 0,
x_exp_a1 = 1,
x_med_cde = stats::median(common_case$inflammation_score, na.rm = TRUE),
x_cov_cond = list(age = 60, sex = "女性", smoking = "从不"),
mreg = "linear",
yreg = "auto",
interaction = TRUE,
verbose = FALSE
)
case3_te <- get_effect_row(res_case3, "te")
case3_tnie <- get_effect_row(res_case3, "tnie")
case3_pm <- get_effect_row(res_case3, "pm")
res_case3$evaluation[, c("event_rate", "mreg", "yreg", "interaction", "x_cov_cond")]
#> event_rate mreg yreg interaction
#> 1 0.226 linear survAFT_weibull TRUE
#> x_cov_cond
#> 1 age=60.000; sex=女性; smoking=从不
dplyr::filter(res_case3$result, `Effect code` %in% c("te", "tnie", "pm"))
#> Model Effect code Effect Scale Exposure
#> 1 model_1 tnie Total natural indirect effect Time ratio metabolic_risk
#> 2 model_1 te Total effect Time ratio metabolic_risk
#> 3 model_1 pm Proportion mediated Proportion metabolic_risk
#> Mediator Outcome Exposure contrast Mediator reference
#> 1 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> 2 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> 3 inflammation_score incident_event 较低风险 -> 较高风险 <NA>
#> N Case N Non-event N Total follow-up Estimate 95% CI P value
#> 1 1500 339 1161 19723.5 0.860 0.754, 0.981 0.024
#> 2 1500 339 1161 19723.5 0.396 0.303, 0.518 <0.001
#> 3 1500 339 1161 19723.5 0.107 -0.011, 0.225 0.076
#> Mediator model Outcome model
#> 1 linear survAFT_weibull
#> 2 linear survAFT_weibull
#> 3 linear survAFT_weibull这里事件率是 22.6%,所以 yreg = "auto" 自动切到了
survAFT_weibull。
这时最关键的不是数值大小,而是解释尺度已经变了:
-
te= 0.396 现在应读作时间比,而不是风险比 - 因为它小于 1,所以含义是较高风险组的无事件生存时间更短
-
tnie= 0.860 说明炎症路径同样在指向更短的无事件时间
也就是说,生物学故事还是那条故事,但统计语言必须跟着
yreg 一起变:
-
survCox:说事件瞬时风险更高/更低 -
survAFT_weibull:说无事件时间更短/更长
把 3 个场景放在一起看
dplyr::bind_rows(
case_summary_row(res_case1, "案例 1:稀有结局 + 连续中介"),
case_summary_row(res_case2, "案例 2:稀有结局 + 二分类中介"),
case_summary_row(res_case3, "案例 3:常见结局 + 连续中介")
)
#> 场景 事件率 结局模型 总效应
#> 1 案例 1:稀有结局 + 连续中介 8.7% survCox 1.877 (1.303, 2.703)
#> 2 案例 2:稀有结局 + 二分类中介 8.7% survCox 1.878 (1.304, 2.706)
#> 3 案例 3:常见结局 + 连续中介 22.6% survAFT_weibull 0.396 (0.303, 0.518)
#> 间接效应 中介比例
#> 1 1.246 (1.018, 1.525) 42.3% (2.7%, 82.0%)
#> 2 1.100 (0.920, 1.315) 19.5% (-16.4%, 55.4%)
#> 3 0.860 (0.754, 0.981) 10.7% (-1.1%, 22.5%)把这 3 个场景放在一起看,你会更容易区分 3 类不同决策:
- 中介变量在科学上应该被理解成连续量,还是阈值状态
- 把连续中介二分类后会不会损失路径信息
- 结局不再稀有以后,结果应不应该继续按风险比去读
本节小结
这篇案例教程最希望你带走 6 条实践规则:
-
x_exp_a0和x_exp_a1应该对应你在结果段里真正想比较的暴露对比 -
x_med_cde决定 CDE 是在什么中介水平上被解释的;对连续生物标志物来说,中位数通常是一个干净的起点 -
x_cov_cond决定这些效应是对哪一类人算的;当x_cov里有分类变量时尤其要显式给 - 如果中介在科学上是连续生物标志物,更适合先用
mreg = "linear";如果问题本来就是阈值状态,再考虑mreg = "logistic" -
yreg = "auto"会帮你避开明显不适合继续用survCox的高事件率场景,但最终解释前仍然要先看实际输出里的Outcome model - 中介分析的结论必须来自真实拟合结果本身,而不是来自“画了一张路径图”或者“某个点估计看起来不错”